Ce document expose notre méthodologie pour l'acquisition, la reproduction et l'intégration des flux audio.
Nous y présentons en détail les équipements requis pour sa mise en œuvre, les contraintes techniques identifiées, ainsi que les solutions adoptées, dans le but de proposer une approche fiable, structurée et reproductible.
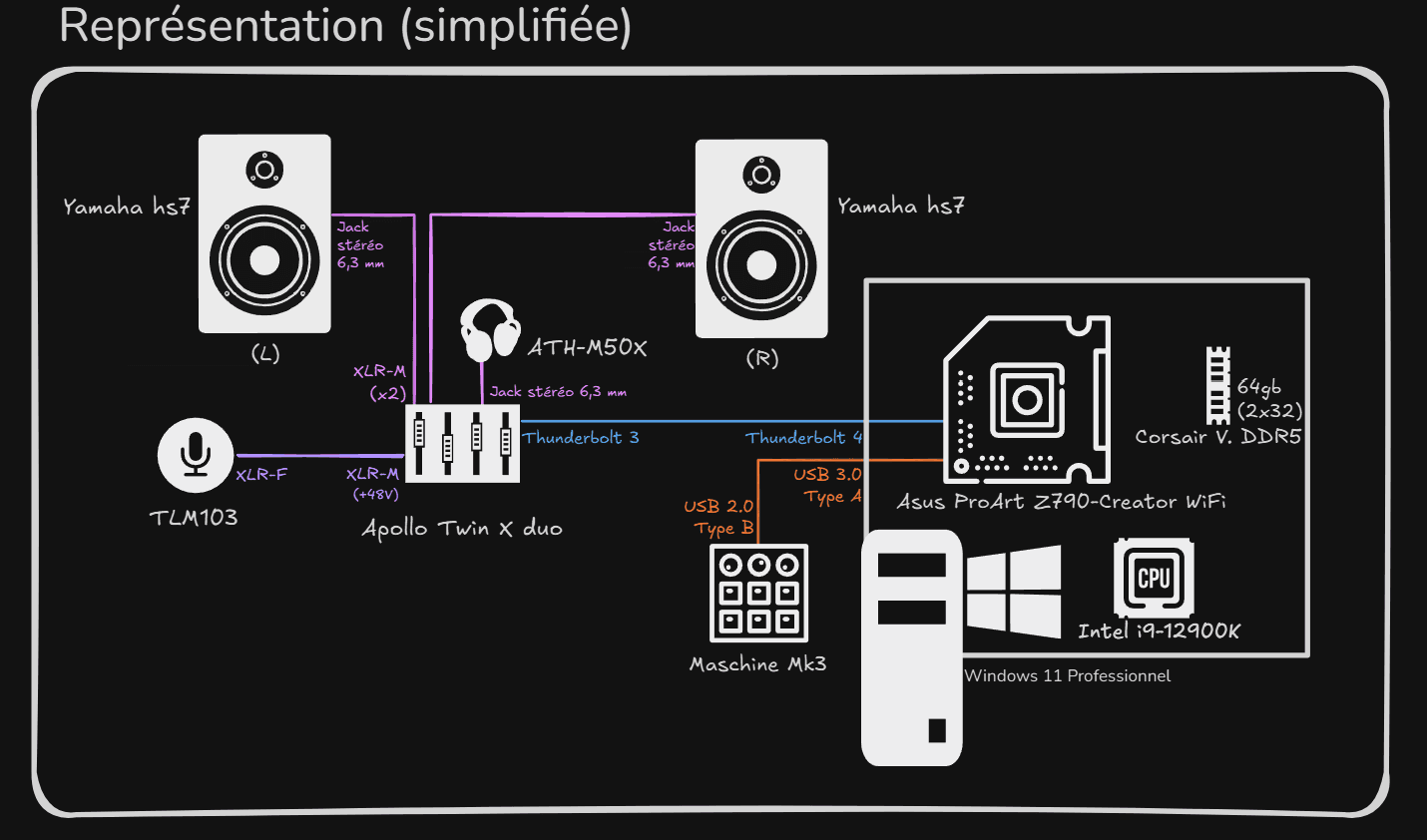
Matériel :
Apollo Twin X (Thunderbolt)
Asus ProArt Z790 (Thunderbolt)
Newmann TLM 103
Native Instrument MK3 (Maschine 2)
Yamaha HS7
Audio technica ATH-M50X
OS :
Windows 11 Pro
Logiciels :
UAD Console
QJACKCTL (x64)
Voicemeeter Potato (x64)
Maschine 2
DaVinci Resolve
Introduction
L'intégration fluide et stable d'une installation audio polyvalente constitue un défi majeur.
En effet, les stations de travail audio sont généralement optimisées pour une tâche spécifique, comme la production ou le mixage, ce qui limite leur capacité à répondre à des besoins variés.
Les exigences liées à la réduction de la latence et au maintien de taux d'échantillonnage élevés imposent des configurations rigides, réduisant leur flexibilité pour des usages plus généralistes.
C’est dans ce cadre que s’inscrit notre démarche.
En travaillant sur deux systèmes d’exploitation distincts, macOS et Windows, nous avons jugé essentiel de maintenir une compatibilité avec les deux plateformes. Ce choix vise à préserver à la fois l’ergonomie et la polyvalence de notre environnement. Nous avons ainsi développé une solution permettant une coexistence harmonieuse entre ces systèmes, répondant à nos besoins techniques sans compromis significatif, bien que l’installation initiale puisse s’avérer exigeante
Objectifs
Notre démarche repose sur la volonté de minimiser les compromis tout en répondant à des usages et besoins variés.
La latence minimale constitue une exigence fondamentale pour garantir un confort de travail optimal.
Une intégration en temps réel des flux audio pour un usage spécialisé (composition en temps réel via le retour vidéo de DaVinci Resolve).
Une exploitation en synergie des diférents écosystèmes audio fournis par Universal Audio, Native Instruments, Waves et autres…
Une station capable de répondre à des usages "loisirs" (Discord, Teams, streaming de médias).
Comme pour toutes nos ressources, nous avons pour pilier la préservation de l'intégrité du signal sonore. Chaque étape de la chaîne d'acquisition, conversion et traitement a été pensée pour garantir un son précis, fidèle et exempt d'altérations.
Chaîne Audio : Description des Éléments
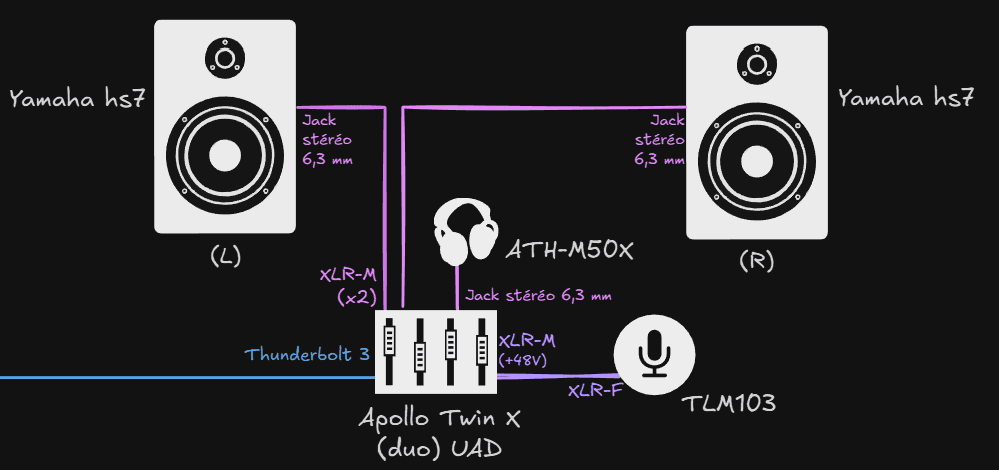
La Carte Son : L'Élément Central

Nous avons opté pour l'Apollo Twin Duo d'Universal Audio. Ce choix s'est imposé car cette dernière réponds à nos attentes, notamment par :
La fidélité des émulations analogiques proposé grâce à la technologie Unison®, cette carte assure une gestion optimale des préamplis et des amplificateurs analogiques, modulant l'impédance de ces dernièrs pour émuler au mieux les outils analogiques proposés.
Une ergonomie intuitive : elle nous permet de contrôler de manière très ergonomique les niveaux de deux entrées (XLR/Line), de gérer indépendamment les retours casque et enceintes, sans latence. De plus, elle offre la possibilité d'appliquer des traitements audio élémentaires directement depuis l'interface. Enfin, elle alimente les microphones compatibles via le phantom power.
Un écosystème de plugins riche : Universal Audio propose une large gamme de VST compatibles, permettant d'accéder à des outils professionnels pour l'enregistrement, le mixage et la production audio
DSP intégrés : Équipée de deux processeurs DSP, l'Apollo Twin Duo permet de traiter les plug-ins Universal Audio en temps réel, sans solliciter les ressources de l'ordinateur. Cette capacité garantit une gestion fluide des effets même lors de projets complexes, tout en assurant une faible latence pendant l'enregistrement et le monitoring.
Le monitoring : Enceinte et Casque

Afin de pouvoir monitorer notre signal sonore fidèlement nous avons optés pour :
Yamaha HS7, des enceintes reconnues pour leur neutralité sonore. Leur réponse en fréquence plate permet de percevoir le son tel qu'il est, sans coloration artificielle. Cela nous garantit une restitution précise du mixage et facilite les décisions techniques pendant la production.
Audio-technica ATH-M50x, casque offrant un compromis idéal entre une qualité sonore honnête et un bon rapport qualité-prix. il offre une reproduction sonore suffisament neutre pour son application dans notre chaine de production.
Le captation de voix : Micro

Le Neumann TLM 103
Dans la même logique que nos choix précédent nous l'avons sélectionné spécifiquement pour sa capacité à capturer les voix de manière fidèle et claire, tout en préservant la richesse et la nuance des détails sonores.
La station de travail : Mobile et Fixe

Par défaut, nous utilisons une station fixe sous Windows, qui constitue notre principale source de puissance de traitement (graphique, processeur, etc.).
Cependant, en mobilité ou pour des traitements légers, nous utilisons un MacBook Pro.
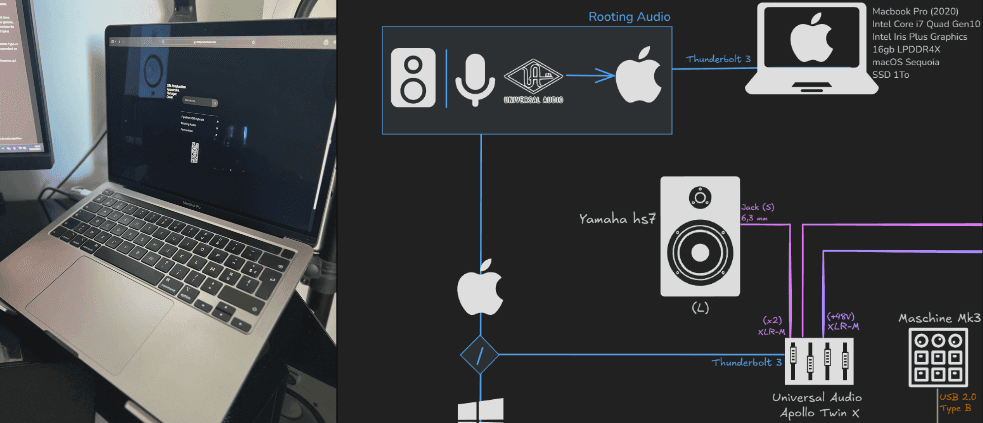
La carte son dispose uniquement d'une connectique Thunderbolt de troisième génération. Son intégration sous macOS est donc particulièrement fluide, puisque le Thunderbolt, est partiellement développé par Apple qui l'inclus nativement dans l’ensemble de sa gamme d’appareils.
Cependant, la connectivité Thunderbolt est rare sur les cartes mères pour stations fixes. En général, elles se limitent au standard plus courant, l’USB Type-C.
Il est essentiel de comprendre qu’une connectique Thunderbolt (4ème génération) est systématiquement rétrocompatible avec le Type-C. Car sa capacité de transfert est plus élevée.
À l’inverse, une connectique Type-C standard ne peut pas gérer le Thunderbolt, faute d'un débit plus bas.
Deux solutions s'offrent à nous :
Opter pour une carte mère intégrant nativement du Thunderbolt 4.
Installer une carte d'extension PCI Express pour ajouter cette connectique.

Nous avons choisi la Asus ProArt Z790, qui supporte nativement le Thunderbolt 4, optimisant ainsi l'intégration sans occuper un port PCI Express déjà utilisé par notre DeckLink Mini Monitor 4K
(référence : Pipeline HDR Hybride )
Composition : Le controlleur
Pour la composition, nous avons opté pour le MK3 de Native Instruments, un choix motivé par sa polyvalence et son aspect complet nous permettant de composer exclusivement via le controleur.
En ce dernier se distingue par son intégration fluide de Maschine 2 (DAW), offrant une véritable fluidité dans la composition. Les banques de sons de haute qualité proposées par Native Instruments enrichissent couvrent divers styles et ambiances ce qui répond parfaitement à nos besoins.
Loisir : Communication
Bien que non essentiel à cette pipeline, nous avions évoqué lors de l’élaboration de ce système une volonté de polyvalence et de loisir.
L’objectif était de pouvoir contourner toute cette procédure dans un usage purement récréatif, en allumant simplement un casque pour en profiter instantanément.
Nous avons donc décidé d’inclure un casque gaming sans fil avec un dongle USB (tout casque sans fil doté d’un récepteur USB peut le remplacer dans cette installation).

Notre choix s’est porté sur le Sony H9, qui, grâce à son dongle récepteur, nous offre un son qui bien que coloré répond agréablement à un usage loisir. Il propose également une spatialisation stéréo, une réduction de bruit active, ainsi qu’un micro intégré, ce qui nous permet de profiter confortablement de notre station de travail dans un cadre récréatif.

À noter que le récepteur dispose d’un interrupteur permettant de basculer entre un protocole audio PC et un protocole PlayStation 5, choix qui s'intégre parfaitement dans notre écosystème de loisir Sony.
Rooting Audio (Logiciel)
Avant de procéder, nous allons introduire deux notions essentielles pour comprendre cette partie : l’échantillonnage (sampling) et le buffer (tampon).
L'Échantillonnage (ou Sampling)
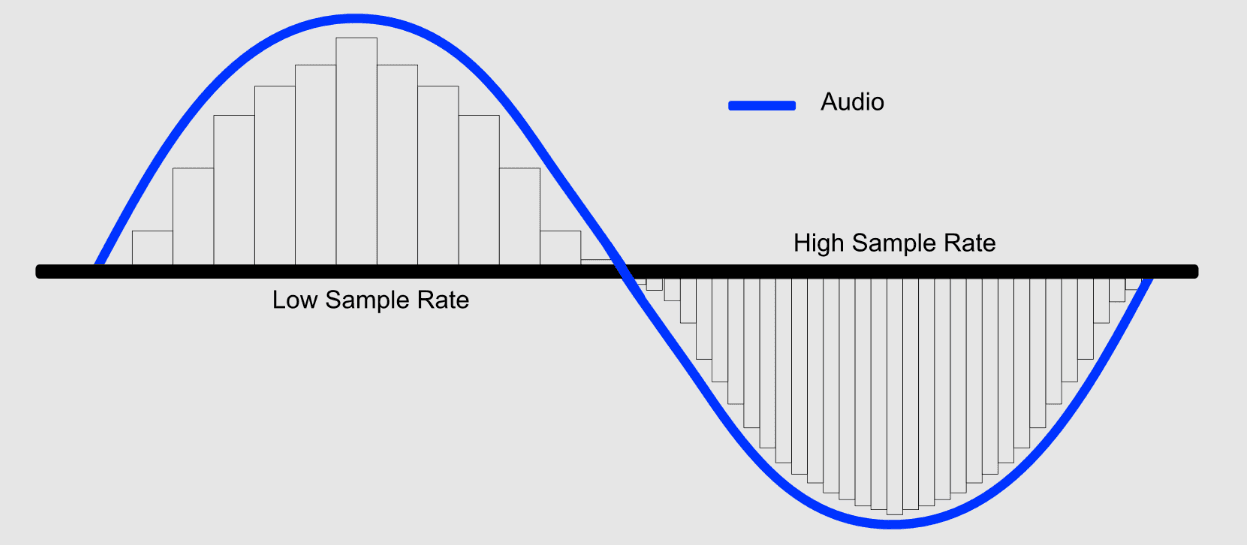
L’échantillonnage est le processus par lequel un signal audio continu (analogique, comme celui d'une voix ou d'un instrument) est converti en un signal numérique, représenté sous forme de bits.
Ce processus consiste à prélever des "échantillons" du signal à intervalles réguliers. La fréquence à laquelle ces échantillons sont prélevés est appelée fréquence d’échantillonnage (représentée sur l’axe horizontal du schéma).
Cette fréquence, exprimée en hertz (Hz), elle indique le nombre d’échantillons capturés chaque seconde.
Une fréquence d’échantillonnage élevée, tout comme une résolution plus élevée en imagerie, produit un signal numérique plus fidèle au signal audio d'origine, car elle réduit les approximations liées à la conversion.
(source: https://www.hollyland.com/blog/tips/what-is-sample-rate-in-audio )Par exemple :
Une fréquence d’échantillonnage de 44,1 kHz signifie que le signal est échantillonné 44 100 fois par seconde.
Une fréquence plus élevée améliore la fidélité du signal mais augmente également la taille des fichiers audio et la puissance de calcul nécessaire.
Le Buffer (ou Tampon)
Le buffer est un espace mémoire temporaire qui stocke les données audio avant qu'elles ne soient traitées ou envoyées à l’interface audio (par exemple, une carte son).
Son rôle principal est de compenser les écarts de vitesse entre différents processus :
Le traitement logiciel du signal audio.
La lecture/écriture des données par l’interface audio.
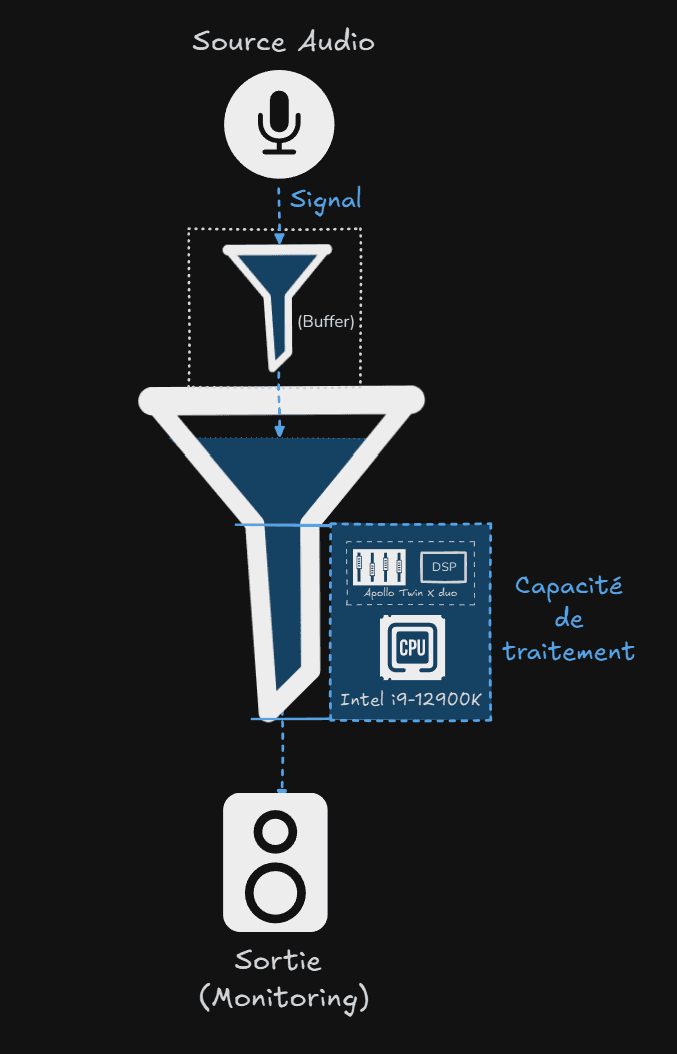
Analogie de l'entonnoir :
Le goulot de l’entonnoir représente la capacité de traitement (calcul), déterminée par le processeur de l’ordinateur et les processeurs DSP (Digital Signal Processors) de la carte son.
La vitesse d’écoulement correspond au délai du retour audio. Plus le liquide met du temps à s'écouler, plus le retour sera long. Il faut alors soit réduire la quantité de liquide versé (sample rate), soit augmenté le goulot (la puissance de calcul)
Dans notre situation, on cherche à avoir le meilleur compromis entre la vitesse d'écoulement (délai) et le volume versé (sample rate).
Si ce compris est mal évalué, alors le volume de données (signal audio échantillonné) dépasse la capacité d'écoulement du goulot, l’entonnoir déborde.
Le signal est alors instable, ce qui se traduit concrétement par des artefacts sonores aléatoires rendant le signal innexploitable (coupures, crépitements, pops).
Le buffer intervient alors pour réguler la vitesse d’écoulement des données, afin d’éviter ce débordement.
Toutefois, cette régulation se fait au prix de l’introduction d’une latence proportionnel au Buffer choisi, plus cette valeures est importante, plus on "retient" le signal audio en amont afin d'éviter de dépasser notre capacité de traitement.
La taille du buffer joue donc un rôle crucial dans l'intégrité du signal :
Un buffer trop petit risque de ne pas retenir suffisament le flux audio ce qui résulte au même scénario de débordement qui induit des coupures audio ou des artefacts sonores, car le processeur ne peut pas traiter les données assez rapidement.
Un buffer trop grand, en revanche, introduit une latence notable, ce qui devient problématique dans des contextes nécessitant une performance en temps réel, comme l’enregistrement, la composition en temps réel ou le monitoring en direct.
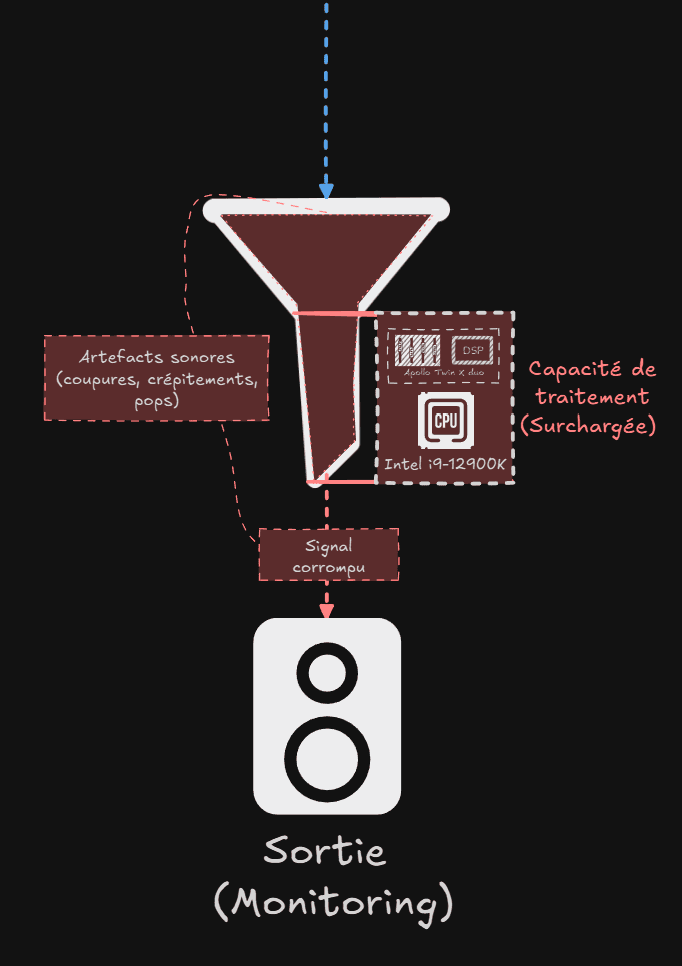
Dans une chaîne audio, il est crucial de comprendre qu'un processus mal synchronisé, tel qu'une mauvaise assignation du buffer ou un échantillonnage incorrect, entraîne aléatoirement des artefacts sonores.
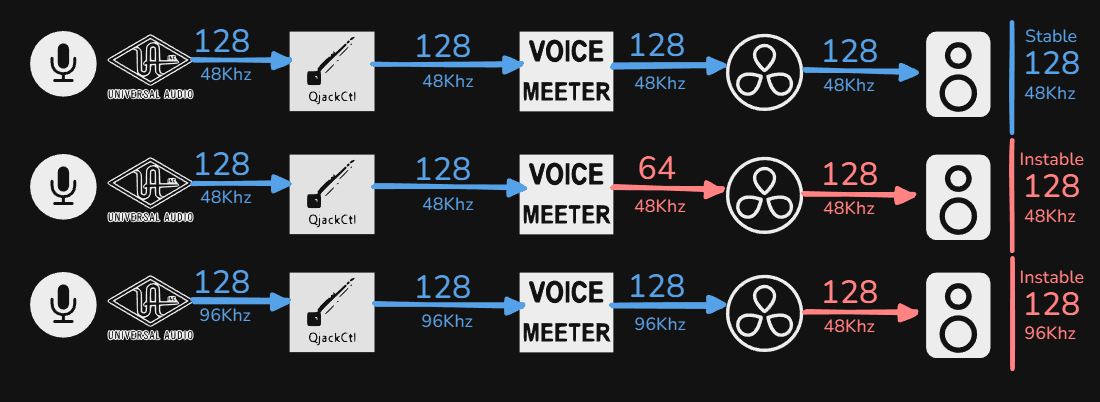
La carte son joue un rôle central dans cette chaîne, car elle est l'autorité principale en matière de gestion des buffers et du timing. Tous les processus logiciels doivent donc se conformer à ses paramètres.
La latence, qui dépend en partie de la taille du buffer (buffer size), ne s’additionne pas de manière linéaire entre différents composants.
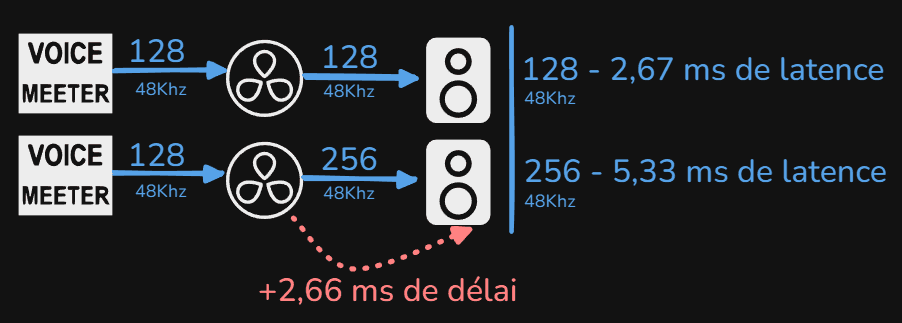
Par exemple, si la carte son est configurée avec un buffer size de 128 échantillons et que le logiciel utilisé (par exemple, DaVinci Resolve) est également paramétré sur un buffer size de 128 échantillons, la latence globale correspondra à celle d’un buffer unique de 128 échantillons. (128 | 128 → sortie en 128)
En revanche, si la taille du buffer est augmentée à un certain point dans la chaîne (par exemple, à 256 échantillons en fin de boucle), la latence globale sera dictée par le buffer le plus élevé dans la chaîne, soit 256 échantillons dans ce cas. (128 | 256 → sortie en 256)
Cela nous amène au premier problème rencontré : les conflits de priorité entre les pilotes audio natifs de Windows (WDM) et ceux de notre carte son (Universal Audio Driver)

Dans la majorité des logiciels spécialisés, il est possible de contourner le système audio natif de Windows. Cependant, cette approche entre en contradiction avec notre intention initiale, car elle impose une gestion au cas par cas des logiciels, rendant l’exploitation fragile en raison de la redondance des paramètres à adapter pour chaque situation.
Par ailleurs, certaines applications, notamment celles qui ne sont pas centrées sur le traitement audio, ne permettent généralement pas d’assigner un moteur audio spécifique et utilisent par défaut celui de Windows (WDM). C’est le cas de logiciels comme Discord, les navigateurs web, etc.
Cette situation entraîne des conflits au niveau de l’échantillonnage et de la taille du buffer. Lorsque ces paramètres ne sont pas alignés, cela engendre des artefacts sonores aléatoires, rendant leur exploitation chaotique.
Ne pouvant harmoniser ces derniers de manière uniforme, notre solution a été de traiter le son en cascade et d’appliquer la chaîne suivante afin de conformer notre signal :
Entrée - (Microphone) → Interface Universal Audio (conversion analogique-numérique).
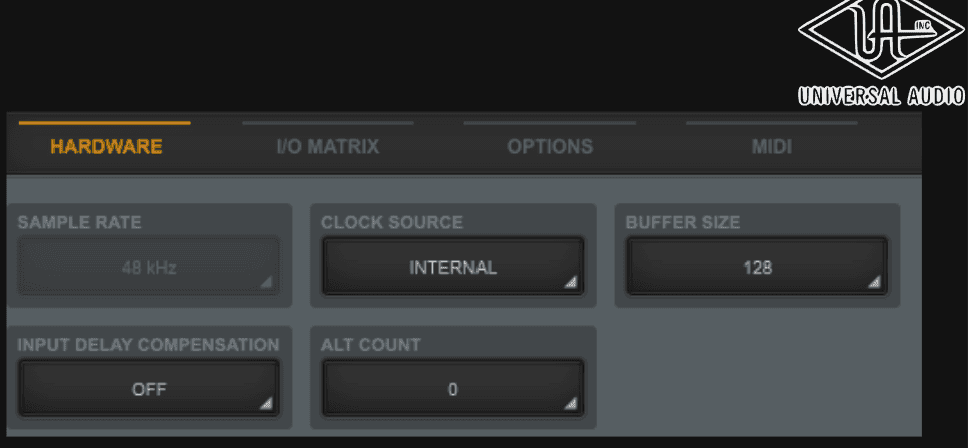
Paramètres fixés sur l’interface Universal Audio (Console) :
Échantillonnage (Sample Rate) : 48 000 kHz
Taille du buffer (Buffer Size) : 128 échantillons
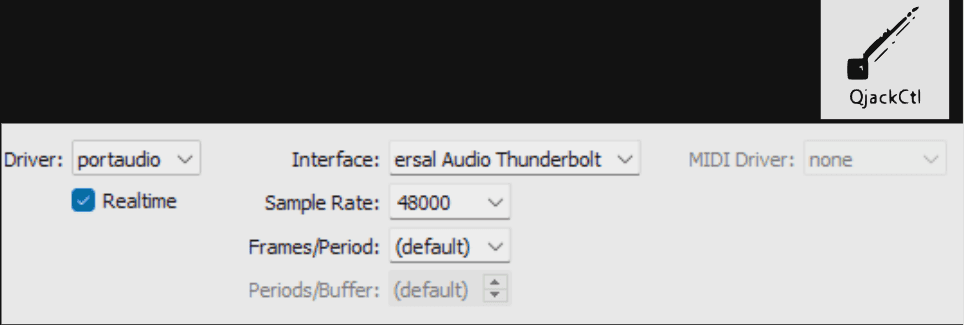
QjackCtl → Gestion des connexions audio avec QJACK. (émulation)
Les mêmes valeurs d’échantillonnage et de buffer sont configurées dans QjackCtl pour garantir la cohérence de la chaine.
VoiceMeeter → Mixage et traitement du signal audio.
VoiceMeeter détecte automatiquement les valeurs configurées dans les étapes précédentes.
Il est pertinent, dans notre contexte, d'assigner à notre entrée la valeur 1-1 (canal gauche-droite), car la source provenant de notre microphone TLM103 est une source mono.
Dans l’onglet de configuration de VoiceMeeter, les valeurs de buffer liées à l’échantillonnage doivent être assignées manuellement pour correspondre aux réglages précédents.
Maintenant que notre signal est stable, on va se focaliser sur sa distribution.
Configuration de la Carte Son
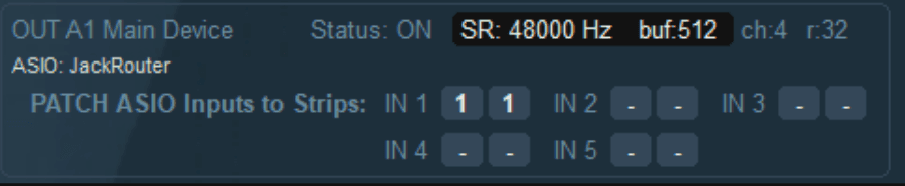
Dans un premier temps on doit configurer notre carte son "Univeral Audio Apollo Twin X Duo" dans l'application "UAD Console"
On arrive alors dans une réprésentation graphique de nos entrées et sorties analogiques :
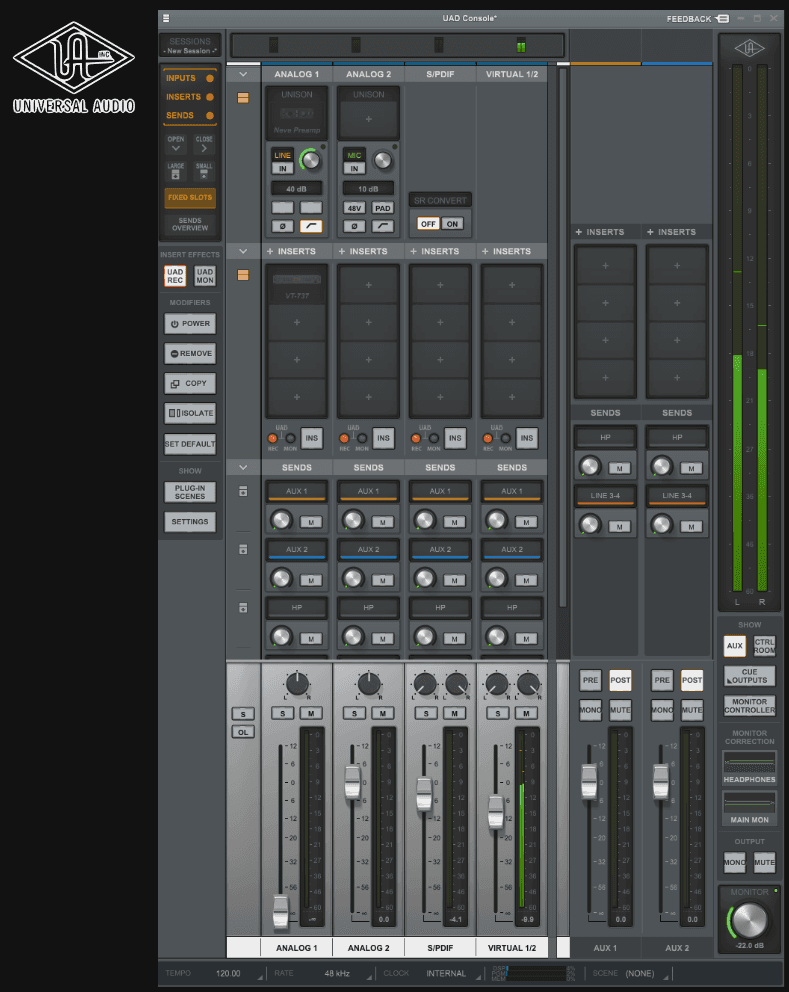
Un des avantages mentionnés précédemment dans le choix de cette carte son réside dans la présence de deux microprocesseurs DSP. Ces processeurs, internes à la carte son et spécialisés dans le traitement audio, permettent de traiter directement les pistes via l'interface audio, déchargeant ainsi le processeur de l'ordinateur de cette tâche. Cela contribue non seulement à alléger la charge du CPU, mais aussi à minimiser la latence. Tous les traitements internes à l'interface sont effectués par les DSP, garantissant ainsi une gestion efficace du traitement audio.

DSP (Digital Signal Processing) :
Le DSP représente la puissance de calcul utilisée pour traiter les plugins. Les interfaces audio UAD sont équipées de processeurs DSP qui prennent en charge l'émulation des effets et des plugins, permettant de libérer la charge sur le processeur de l'ordinateur. Chaque plugin que vous utilisez sur votre DAW (station de travail audio numérique) peut consommer une certaine quantité de puissance DSP. Sur le mixer UAD, DSP vous montre la quantité de ressources DSP utilisées et disponibles.
PGM (Program) :
PGM fait référence à l'utilisation du processeur pour un programme particulier ou un plugin spécifique. Il indique la quantité de ressources DSP utilisée par un plugin particulier. Par exemple, un plugin de réverbération ou un égaliseur pourrait avoir un certain nombre d'unités PGM, et cela vous permet de savoir si vous atteignez la limite du processeur pour ce programme en particulier.
MEM (Memory) :
MEM désigne la mémoire utilisée par les plugins sur l'interface audio UAD. Contrairement au DSP qui mesure la puissance de traitement, MEM fait référence à la quantité de mémoire nécessaire pour exécuter ces plugins. La gestion de la mémoire est importante, car un nombre excessif de plugins ou des plugins complexes peuvent consommer une quantité importante de mémoire et limiter l'utilisation de nouveaux effets dans un projet.
Pour configurer ces derniers, il suffit d'ouvrir l'onglet des options et de se rendre dans la catégorie 'Hardware'. C'est dans cette section que l'on peut répartir nos pistes virtuelles et la charge DSP grâce à la fonctionnalité de DSP Pairing.
Cette option permet d'assigner un ou plusieurs processeurs DSP à un même flux audio en fonction des besoins. Dans notre configuration, nous appliquons un ratio de répartition de 1:2, ce qui signifie qu'un seul processeur DSP est partagé entre deux canaux virtuels
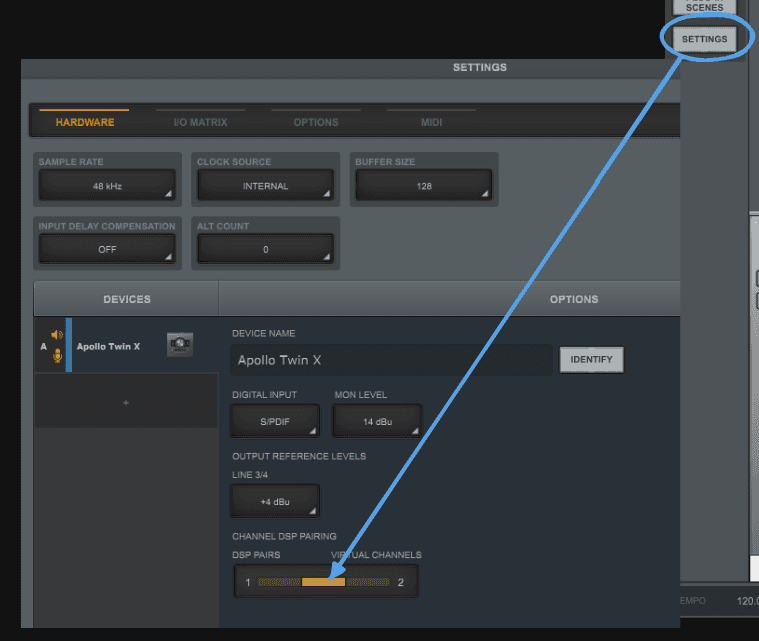
On bascule sur l'onglet des options pour accéder à notre matrice d'entrée et sorties :
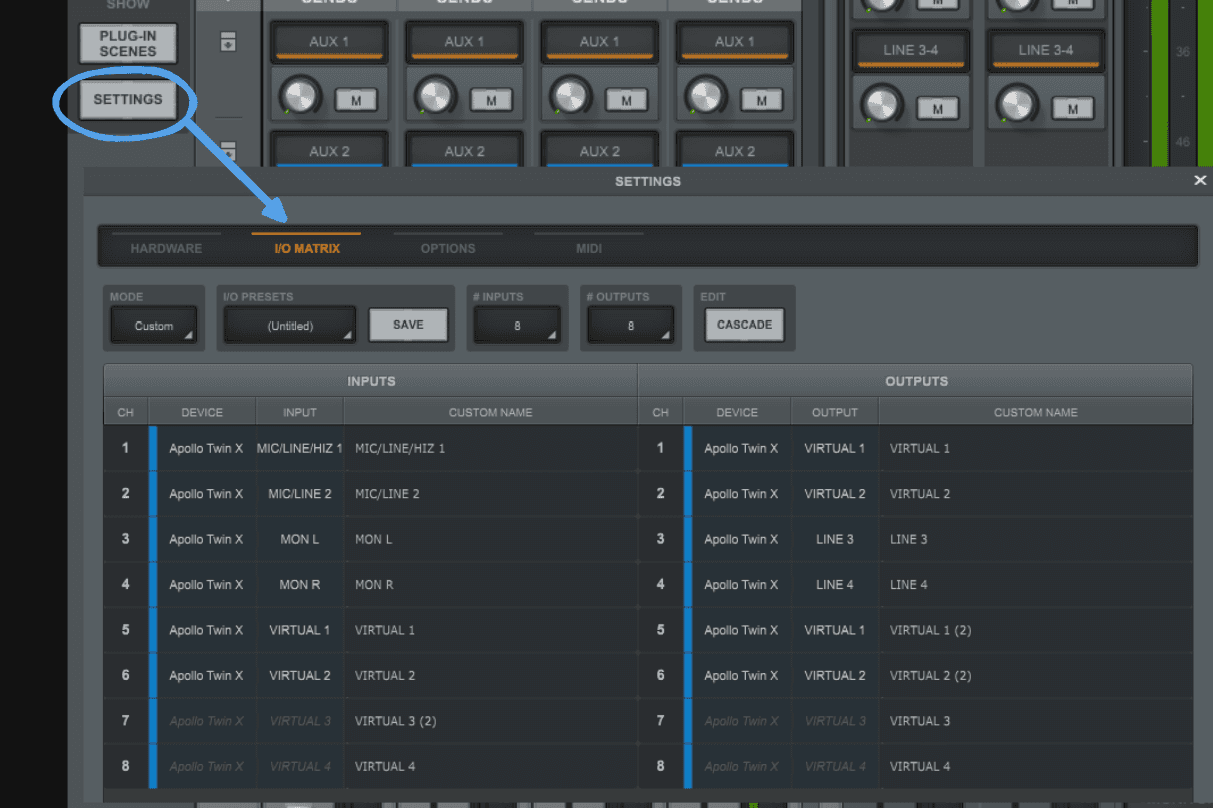
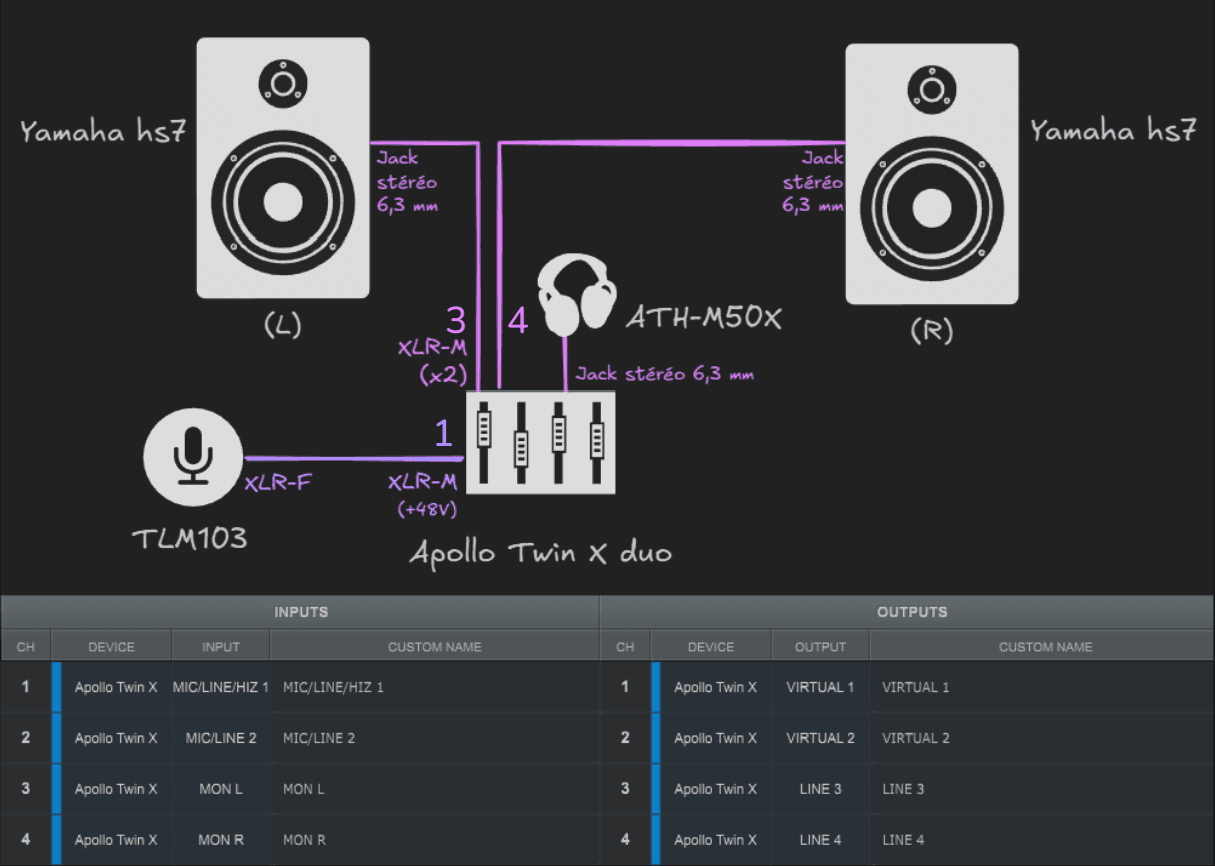
Nous assignons ensuite nos entrées et sorties aux branchements correspondants de notre installation :
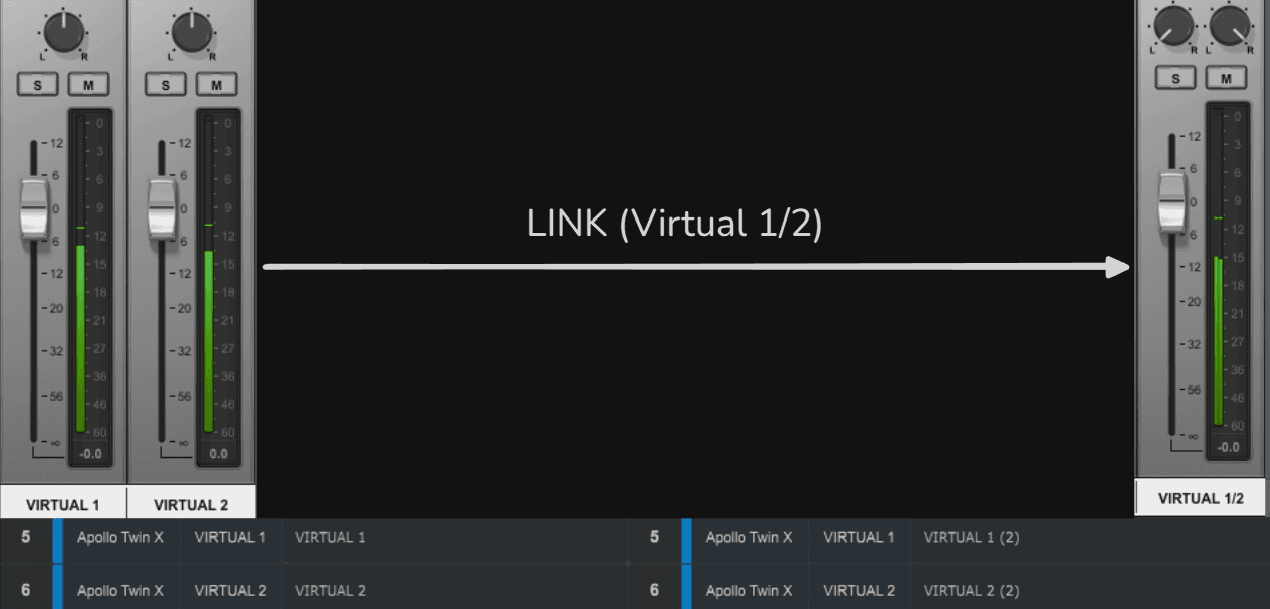
Pour le retour en stéréo, on lie les tranches Virtual 1 et 2. Elles seront alors fusionnées et spatialysées (pan) automatiquement, de gauche à droite.
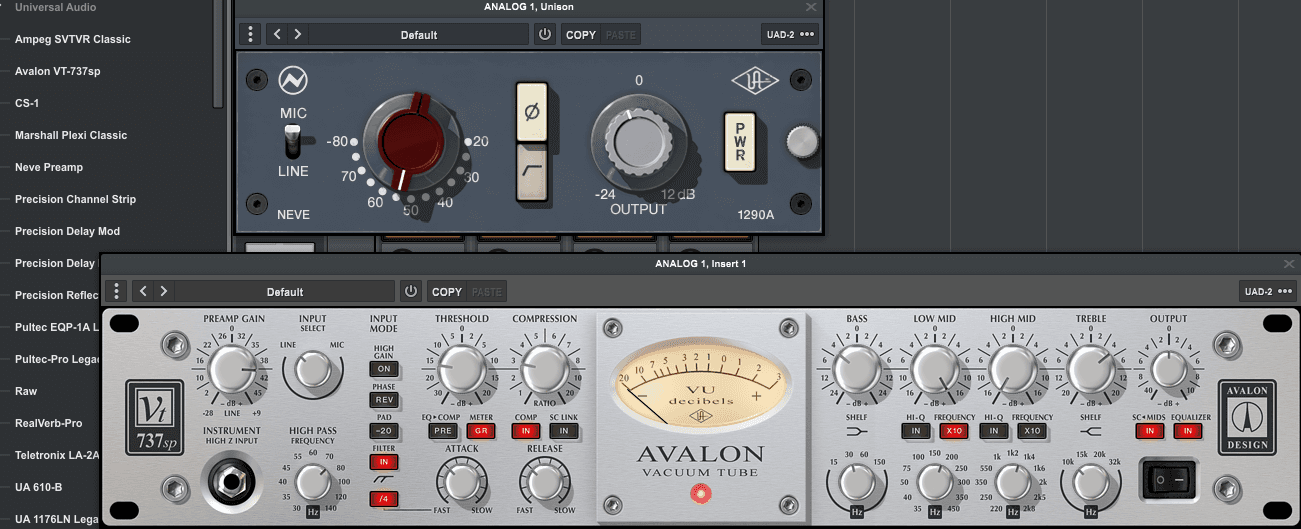
Il est essentiel de comprendre pourquoi l’utilisation des emplacements Unison® est pertinente.
Ces emplacements permettent d'assigner un plug-in du catalogue Universal Audio, lequel sera émulé de manière précise grâce aux préamplis (impédance/gain) de la carte son. Cette approche est particulièrement importante dans une démarche de reproduction, car elle recrée fidèlement le comportement électrique 'unique' d’une tranche analogique, reproduisant ainsi l’interaction spécifique entre l’équipement analogique et notre signal audio.
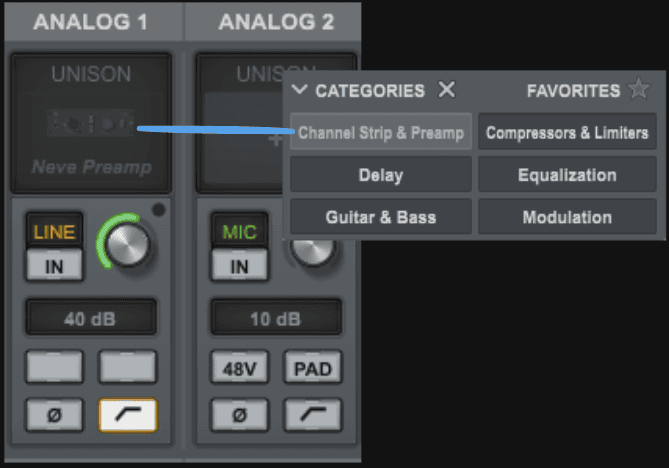
En descendant dans la tranche, on remarque quatre emplacements d'insert. Ces derniers peuvent être utilisés pour appliquer des traitements qui ne seront pas émulés par le préampli, mais qui seront néanmoins calculés grâce à la puissance de traitement de la carte son.

À l'instar d'une chaîne analogique, il est possible de choisir d'imprimer un comportement spécifique sur le signal d'entrée, lequel est intégré dans sa structure avant d'être envoyé à l'ordinateur.

Gestion du signal audio en sortie de console (Windows) :
L'étape précédente dans son exécution est valable pour nos deux systèmes, macOS (station portable) et Windows (station fixe).
Cependant, désormais, toute notre chaîne de traitement s'articule autour de l'application Voicemeeter, qu'il convient de considérer comme une émulation virtuelle d'une table de mixage analogique.

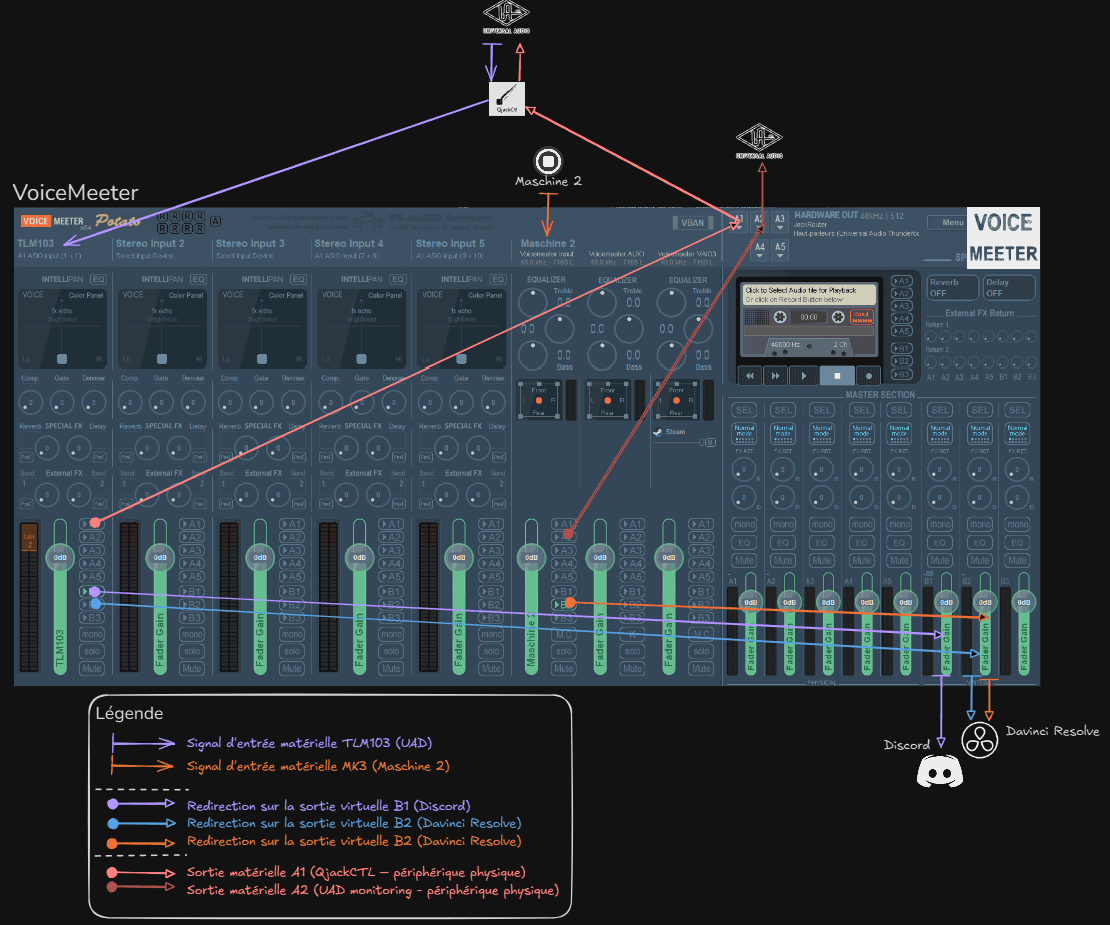
VoiceMeeter crée des entrées et sorties virtuelles similaires à celles physiques de notre carte son :
Pour le retour audio, nous sélectionnons directement la sortie à partir de la source :
Routage Audio avec VoiceMeeter
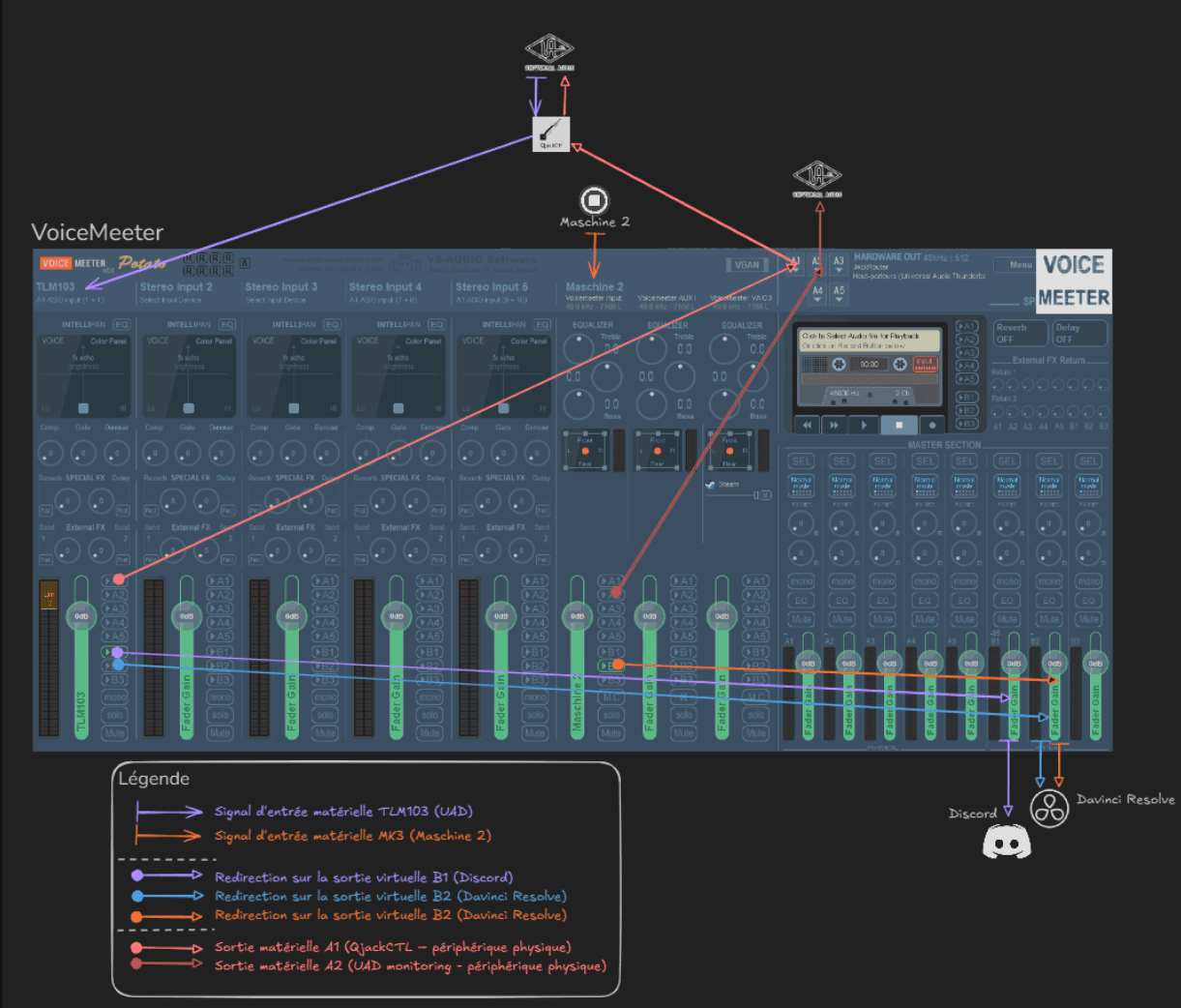
Dans un premier temps, nous allons configurer nos sorties hardware :

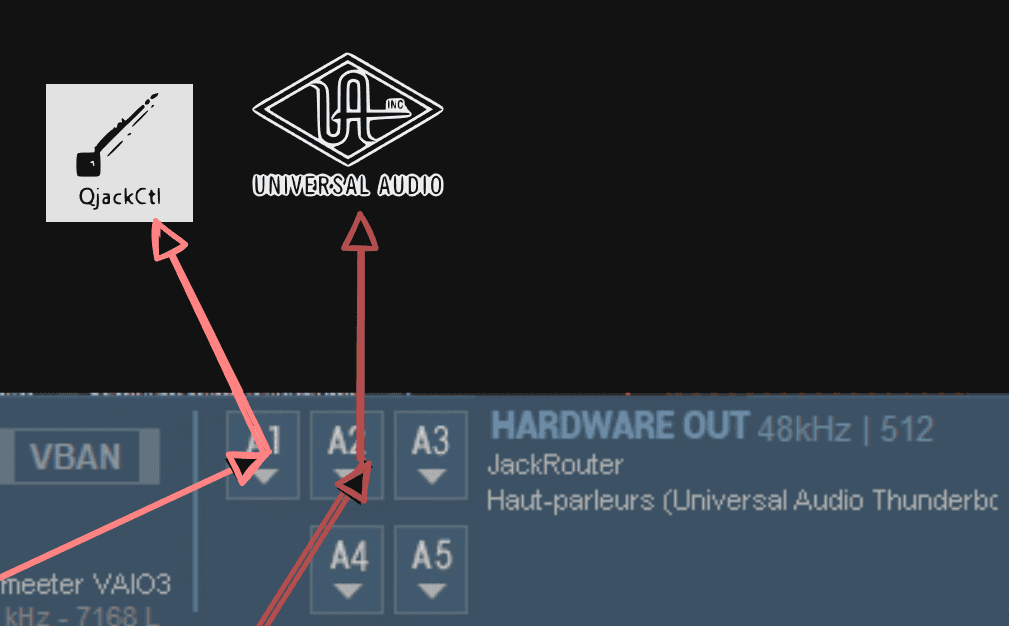
A1 : assigné à QjackCTL (JackRouter)
A2 : assigné à notre sortie audio (UAD)
Nous configurons en suite nos entrées matérielles :

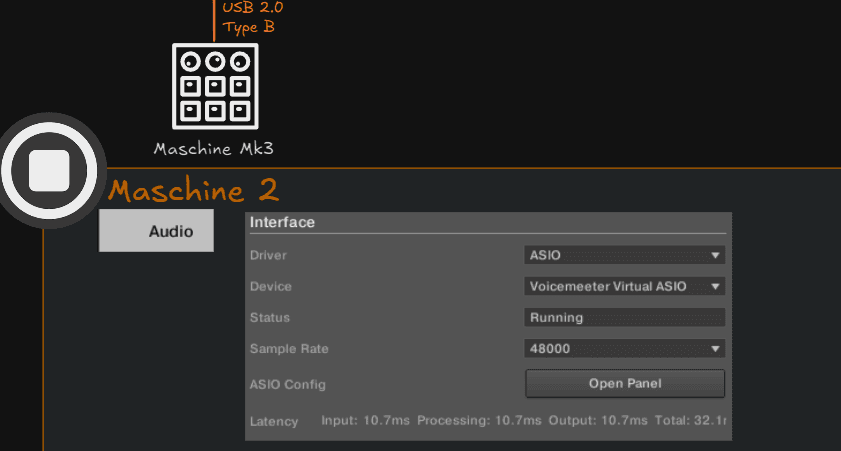
Pour le controleur MK3, on se rend dans les paramètre du DAW qu'il controle : "Maschine 2" et on assigne en driver "ASIO" et en moteur audio "Voicemeeter Virtual ASIO"
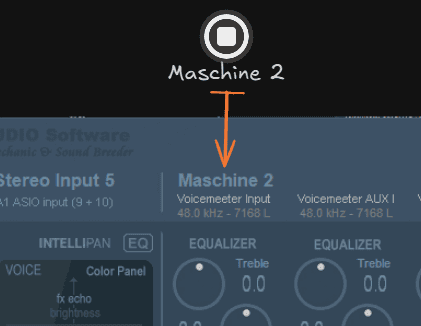
Ce dernier apparait automatiquement dans la tranche virtuelle (5) de Voicemeeter.
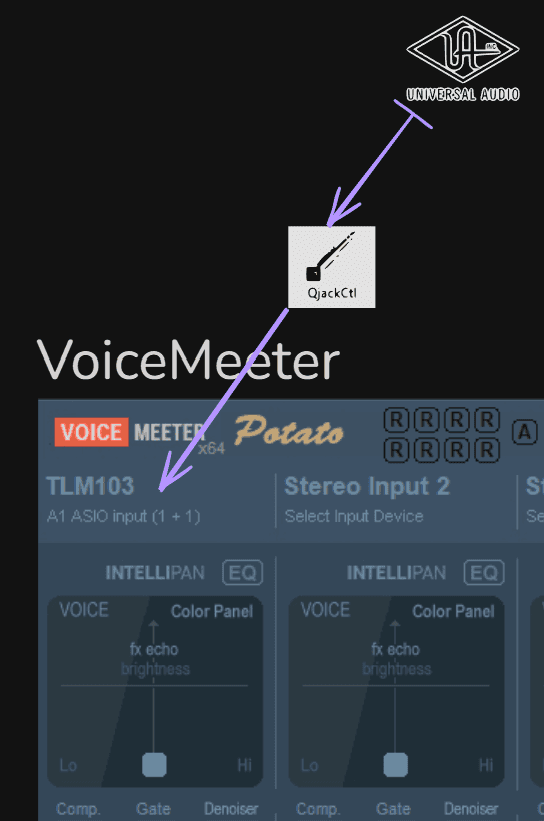
Pour le micro (TLM103) il apparait dans la première tranche (0).
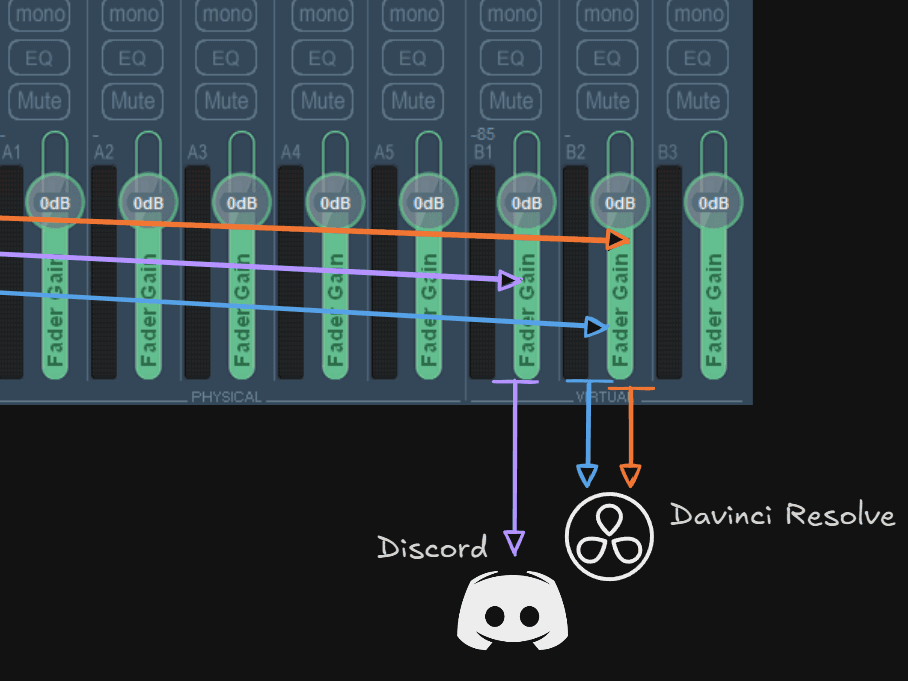
Nous devons maintenant défénir la destination de nos sorties (B1, B2, B3) afin d’assurer une exploitation organisée et efficace :

B1 : configurée comme sortie « par défaut », généralement utilisée pour les communications (Discord, etc.).
B2 : dédiée à une exploitation dans des logiciels spécialisés (comme DaVinci Resolve).
B3 : laissée vide pour le moment, mais réservée à un éventuel usage futur pour un autre flux audio (par exemple, OBS)
Assignation des sorties audio par tranches :
La tranche (0) : correspond à notre entrée micro (TLM103)
Sortie A1 (Rose) : Permet de rediriger le signal via la sortie A1 si l'on souhaite avoir un retour monitoring (casque). Cependant, il est préférable de passer directement par l'interface de la "Console UAD" (en augmentant la tranche Analog 1) afin d'obtenir le signal avec le délai de retour le plus rapide possible.

Sortie B1 (Violette) : Permet de rediriger notre signal vers la sortie de communication par défaut.

Sortie B2 (Bleue) : Permet de rediriger le signal vers notre sortie "Travail", utilisée par toutes les applications professionnelles nécessitant le signal de notre microphone. Ces applications prendront cette sortie comme source (input).
Tranche 5 : correspond à notre entrée virtuelle Maschine 2 (DAW), contrôlée par notre contrôleur MK3.
Sortie A2 (Rouge) : Permet d'avoir un retour monitoring de notre session en temps réel.
Sortie B2 (Orange) : Comme dans l'exemple précédent, permet de rediriger le signal vers notre sortie "Travail", utilisée par toutes les applications professionnelles qui ont besoin de récupérer le signal de notre logiciel.
A cette étape on va défénir notre situation de démarage de Voicemetter (ou scène) :
La Tranche (0) - TLM 103 :
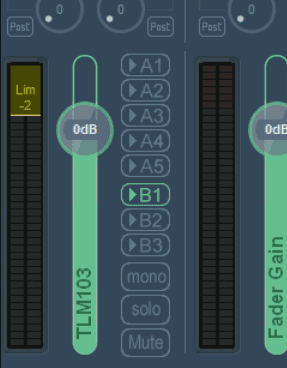
A1 - OFF
B1 - ON
B2- OFF
La Tranche (5) - Maschine 2
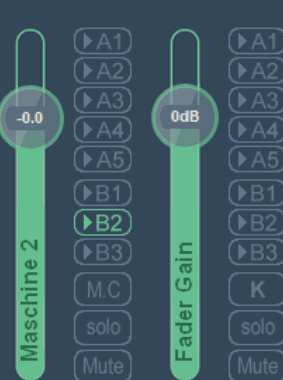
A2 - OFF
B1 - OFF
B2 - ON
A ce stade on enregistre cette configuration et on l'a charge à l'initilisation de Voicemeeter afin de toujours commencer notre initialisation dans cette situation.
Protocole de lancement et automatisation.
Nous avons désormais correctement distribué notre signal pour répondre à nos différentes situations. Nous pouvons donc définir notre protocole de lancement.
Ce protocole est reproductible et doit être exécuté à chaque initialisation de l'ordinateur.
Pour simplifier cette démarche, nous allons utiliser des 'Macros' (automatisation).
Pour cette étape on peut utiliser n'importe quelle support pour assigner les automatisations (clavier, streamdeck..). (en général les supports possèdent leur propre logiciel propriétaire pour assigner des touches supplémentaires)
Dans notre situation, nous utilisons un clavier "CORSAIR K100 air"
Dans le logiciel iCUE de Corsair, nous avons assigné les touches macro 'G2' et 'G3' aux fonctions 'F24' et 'F23', respectivement.

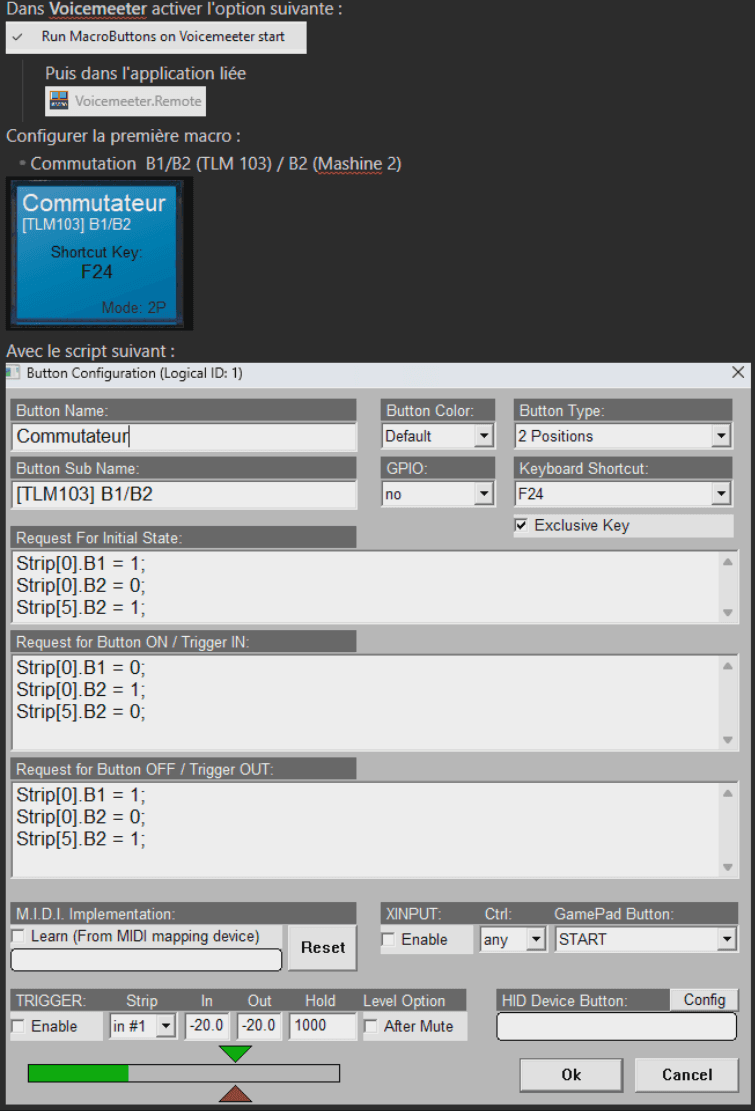
Explication du premier script :
Lorsqu'il est nécessaire de basculer la sortie du microphone TLM103 (Tranche 0) de B1 vers B2 afin de permettre un enregistrement dans un logiciel spécialisé, il est crucial d’éviter que la sortie de Maschine 2 (Tranche 5) soit également dirigée vers B2 simultanément.
Pour garantir cela, le script est conçu de manière à couper automatiquement la sortie B2 de Maschine 2 (Tranche 5) dès que le TLM103 (Tranche 0) est assigné à B2 lors du déclenchement de la macro.
Ainsi, ce mécanisme évite toute collision sonore ou interférence sur la sortie B2, assurant une configuration propre et adaptée à l’enregistrement.
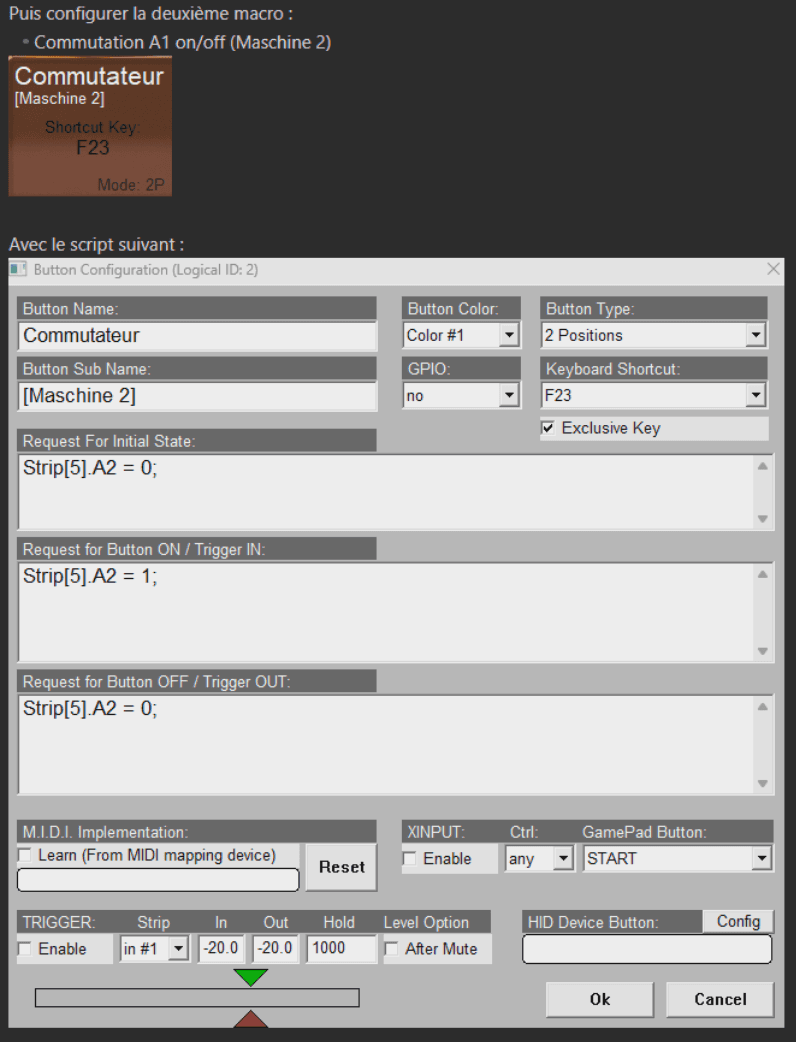
Pour le deuxième script :
Cette automatisation permet la gestion du retour casque lors de l’enregistrement dans "Maschine 2". Plutôt que de modifier manuellement le routage dans l’application à chaque situation, cette macro simplifie le processus.
- Quand la macro est activée : le script active la sortie A2 (monitoring direct) sur la tranche correspondant à la sortie de Maschine 2 (Tranche 5). Cela permet un retour immédiat dans le casque sans passer par un logiciel tiers.
- Quand la macro est désactivée : on repasse au retour fourni par le logiciel externe, comme lors de l’armement d’une piste audio dans DaVinci Resolve, par exemple.
À noter : lors du chargement de la scène dans Voicemeeter (VM), l’état de la macro est défini par défaut sur OFF.
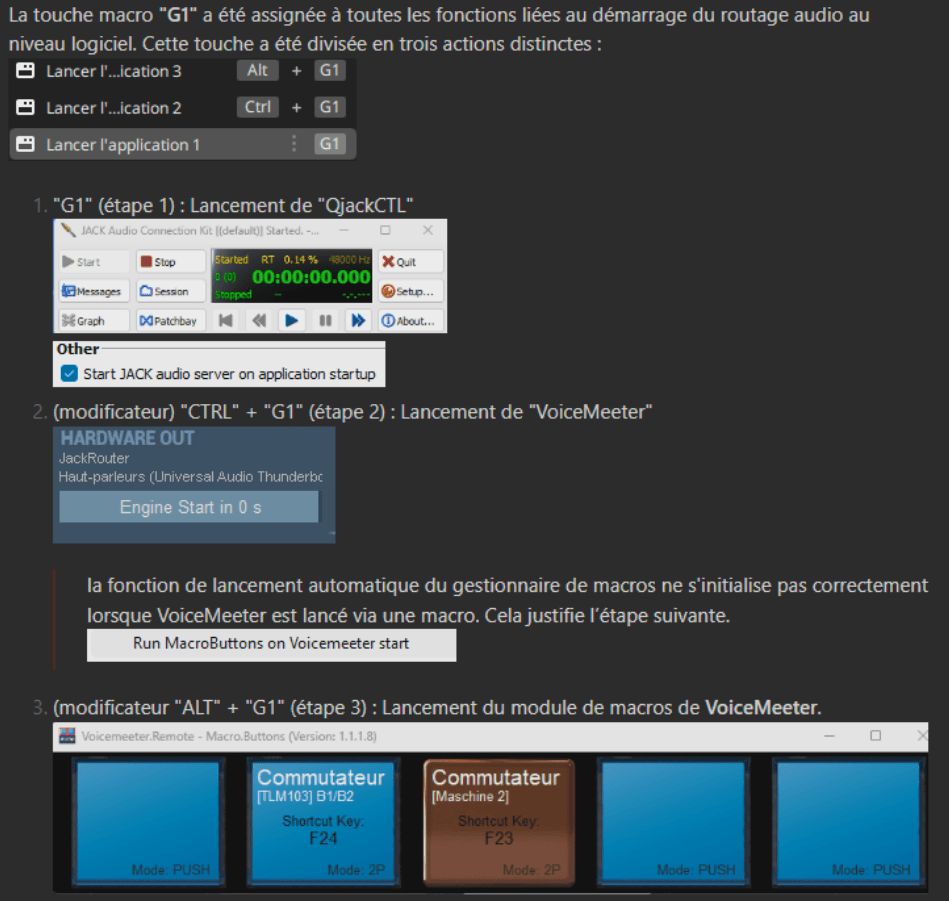
Afin de prolongé cette démarche d'automation et d'éviter des erreurs humaines inhérentes à la répétition de ce protocole de lancement :

Résumé :
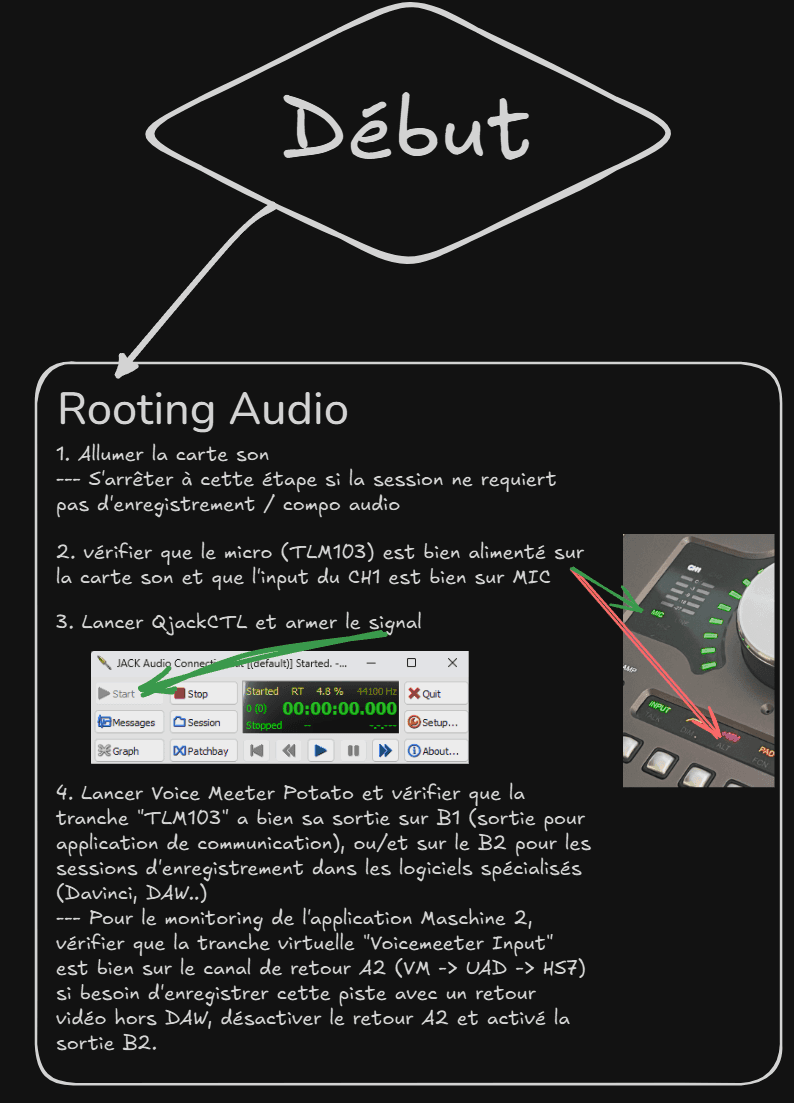
Allumer le matériel de base :
Allumez la carte son et les enceintes de monitoring.
Si la session ne nécessite pas d'enregistrement, cette étape est suffisante.
Préparation pour l'enregistrement (si nécessaire) :
Si un microphone est utilisé, activez l’alimentation Phantom Power (+48V) pour alimenter celui-ci.
Si aucun signal n’a besoin d’être capturé, passez directement à l’étape suivante.
Initialisation de la chaîne audio :
Appuyez sur les touches macros dans l’ordre suivant pour lancer les outils nécessaires :
G1 : Démarrage de QjackCTL.
Ctrl + G1 : Lancement de VoiceMeeter.
Alt + G1 : Activation de VoiceMeeter Remote pour accéder au module de macros.
Une fois ces étapes réalisées, l'installation est pleinement opérationnelle.
Exploitation du signal dans Davinci Resolve :
Au départ, nous réalisions nos compositions sonores (ambiances) et captations vocales en utilisant des 'timemarks' comme points de référence, puis nous les resynchronisions manuellement pour les aligner au mieux.
Cette approche, bien qu'efficace, manquait de flexibilité et d'un retour immédiat, ce qui la rendait assez rigide. Nous recherchions donc une méthode plus organique et spontanée, avec un retour en temps réel sur la séquence vidéo concernée.
C'est alors que nous avons intégré DaVinci Resolve à notre flux de travail.
Dans un premier temps, il est nécessaire de configurer les paramètres audio de notre séquence et de se rendre dans l'onglet 'Fairlight'.
DaVinci Resolve utilise un échantillonnage par défaut de 48 kHz, ce qui est idéal car notre chaîne de production est également en 48 kHz.
Avant de créer chaque séquence, il est important de se rendre dans les paramètres de celle-ci et d'assigner les options nécessaires dans 'Fairlight'
Dans la même section (lors de la création de la timeline), l'option 'Use fixed bus mapping' doit impérativement être sélectionnée. Cette option permet de garantir une correspondance fixe entre les pistes de la timeline et les bus audio du projet, évitant ainsi tout changement automatique du routage lorsque des modifications sont apportées à la configuration audio.

Il convient de noter qu'une fois la séquence créée et ces valeurs assignées, il ne sera plus possible de les modifier sans supprimer la timeline
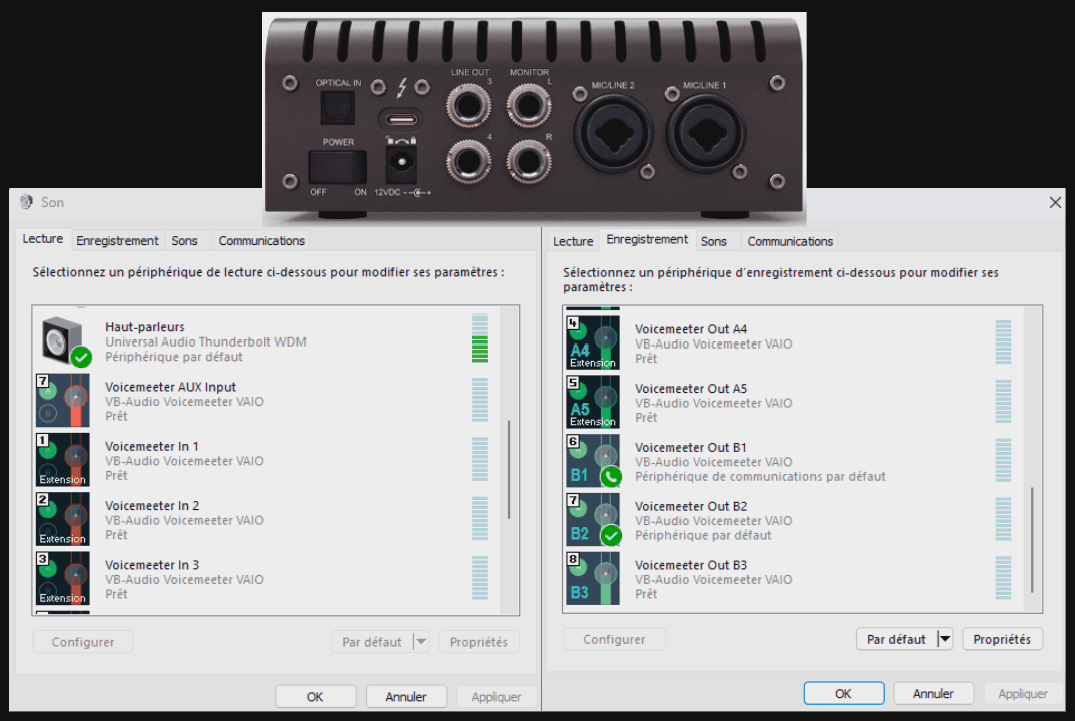
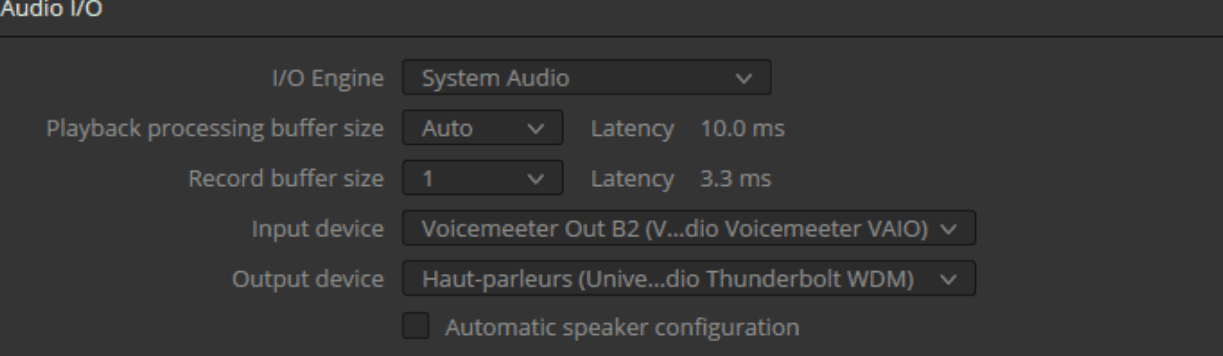
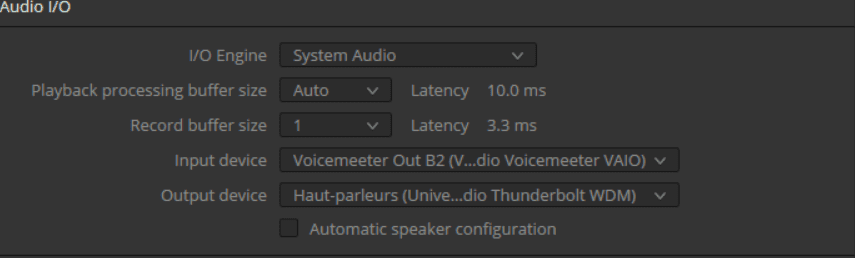
Il est important de s'assurer que dans les paramètres audio de DaVinci Resolve, le routage soit configuré de la manière suivante :
Entrée : Voicemeeter Out B2
Sortie : Haut-parleurs (Universal Audio Thunderbolt WDM)
De plus, vérifiez que la taille du tampon d'enregistrement (Record Buffer Size) est bien réglée sur '1'. Selon la complexité du projet, bien que très robuste, si des artefacts apparaissent pendant l'enregistrement, il sera nécessaire d'ajuster cette valeur à la hausse, par incréments, en tenant compte de l'augmentation du délai.
Dans l'onglet 'Audio' de DaVinci Resolve, on assigne en 'Entrée' notre sortie Voicemeeter B2 et on l'attribue aux pistes concernées (en mono ou stéréo).
On arme la piste en cliquant sur le bouton 'R', ce qui permet d'obtenir un retour audio de celle-ci.
À ce stade, il est important de s'assurer que les retours Voicemeeter (A1-A2) ou la console UAD (Analog 1) sont bien coupés.
Une fois prêts pour l'enregistrement, il suffit de cliquer sur le bouton 'Rec' et la piste commence à dérouler.
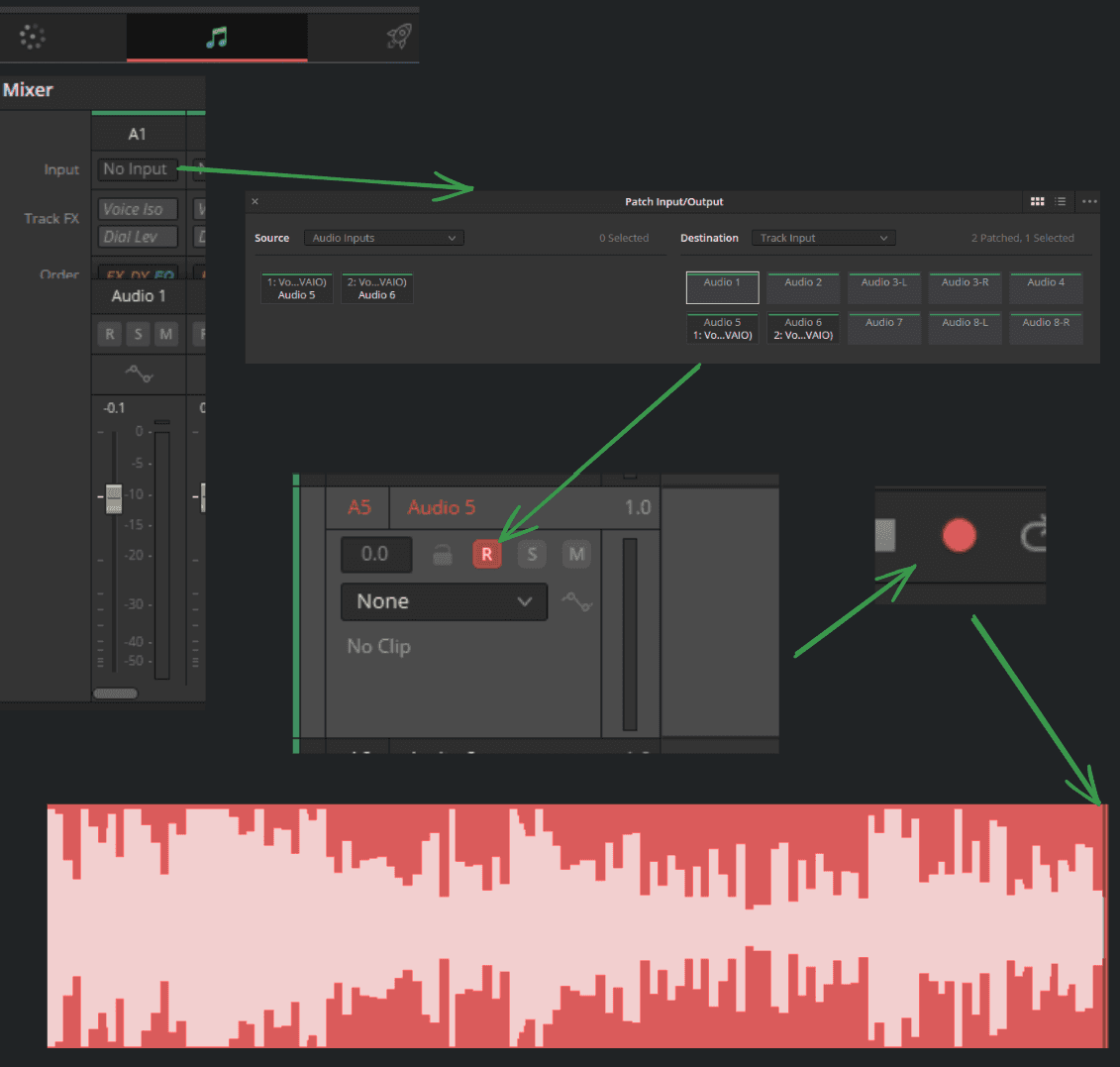
Vous pouvez désormais récupérer le signal de notre sortie B2, conjointement avec les macros associées, pour :
Enregistrer des voix (voice-over)
Composer via le contrôleur de manière synchronisée avec le retour vidéo.
Résolution de problèmes (fréquents)
Système:
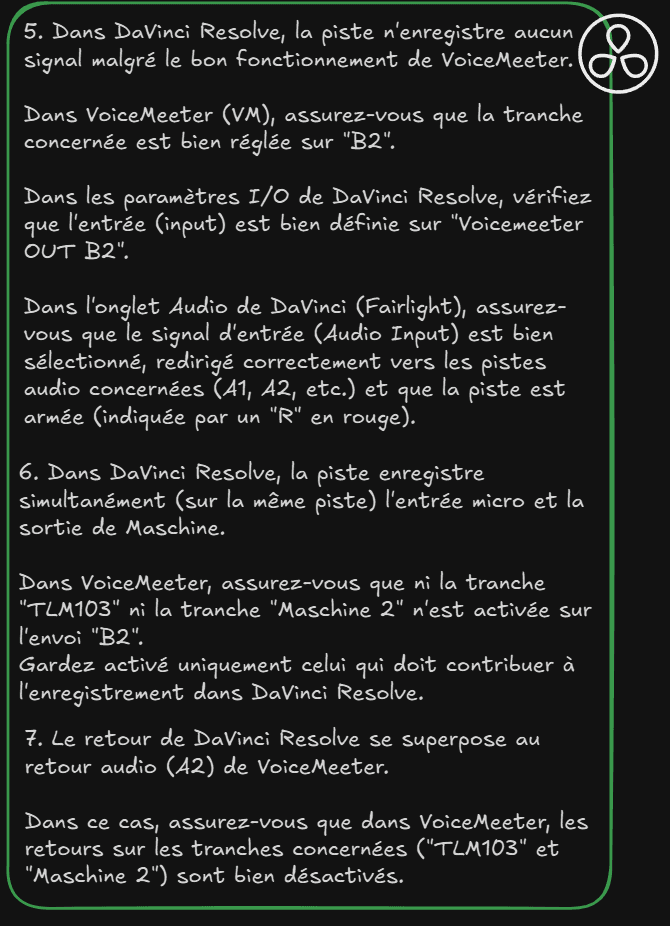
Davinci Resolve:
Avec cette pipeline, vous garantissez un flux de travail stable et fluide dans son éxécution.
N’hésitez pas à adapter ce processus à vos propres équipements et à vos préférences pour en tirer le meilleur parti.
Merci de votre attention.
Crédits
Rédigé par :
Frédéric Karim NAUCHE
Fondateur de 334production
© 2025 - 334Production. Tous droits réservés.
La reproduction, la diffusion ou l'utilisation de tout ou partie de ce contenu, sous quelque forme que ce soit, est interdite sans autorisation préalable.
Contact : contact@334production.com
Pour consulter nos mentions légales, veuillez visiter www.334production.com/mentions-legales
Rooting Audio
Audio

